A deep dive of the building blocks required to create First Principles Supply Chain solution approach that has the ‘potential’ to be responsive, harnessing rich contextual information in supply chains
Summary: Supply chains are notorious for disconnected siloes of systems, processes, technologies, echelons, and local optimizations. But Supply Chains are also rich in context, i.e., information on dependencies, relationships and facts related to a decision or an action. This contextual information is everything in being meaningfully responsive. In a physical world with realities that change every minute – this context keeps changing . Modelling such system requires capturing and amending the context dynamically and in sync with the pace of change, not the over simplistic, rigid approaches that ignore this rich data and hence cannot contextualize.
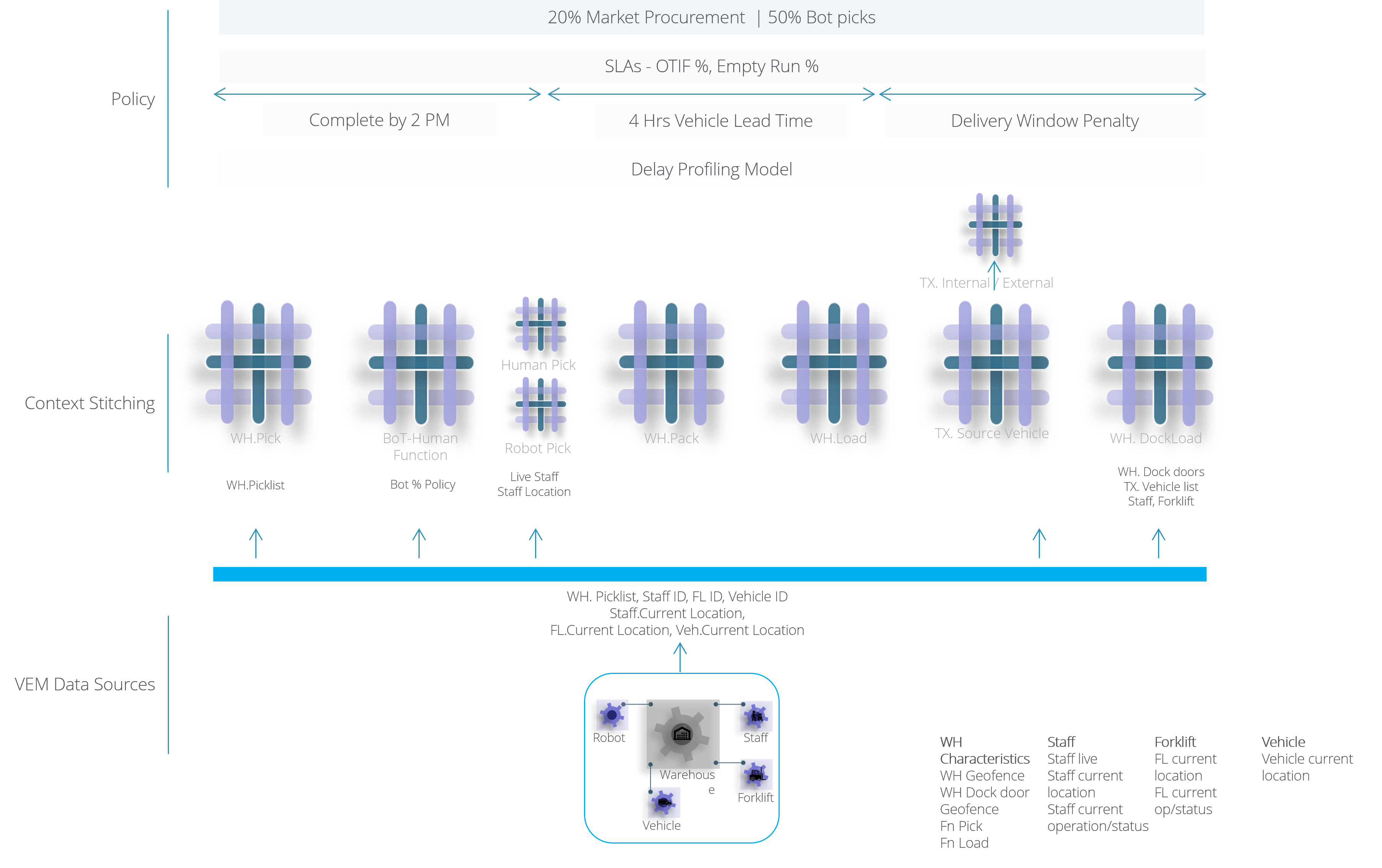
This is a deep dive of a solution approach for a grounds-up, first principles Supply Chain Tech solution. The summary solution description here was of course brief and did not cover differentiating nuances.
Thanks for reading Surendra’s Substack! Subscribe for free to receive new posts and support my work.Subscribe
A few clarifications first:
- As explained in the problem brief here, the core challenge is ‘not capturing data, relationships and related changes’ in a sufficiently quick manner – before the next action or decision. Hence the point is 1/ To capture relevant data and relationships in a dynamic environment which is always changing. 2/ To create a meaningful context stitching this data together, as rapidly as the changes occur. So, this is a data and context creation challenge, not optimization / operations research / AI or product strategy challenge.
- Everything else – KPIs, Dashboards, optimizations using operations research, exact algorithms or heuristics, AI, Gen AI etc., will benefit once the above is solved for, which is complementary to these aspects. This just makes them more effective and expands applicability of AI to more use cases, especially in the field of operations – manufacturing floor, transportation, warehouse, forecasting response by category managers / store managers, supplier rating by inbound QC manager etc., endless possibilities.
With that quick refresher, here we start.
The first principles end-goal is to have a “designed for resilience, end-to-end, ML driven supply chain platform focused on ‘flow’ of goods, placing the right goods at revenue-appropriate time with minimal waste of physical and ecological resources, by leveraging ‘contextual intelligence’ to guide the users take right decisions.” This dream solution is contextual, self-aware and processes events in real-time or as-they-occur providing a feedback loop to minimise the deviation – plan vs execution deviation, cost vs margin deviation, revenue vs service levels divergence etc. – whatever is needed by the business. Context / contextual intelligence here refers to information on dependencies, relationships, facts, influencing factors and causations related to a decision or an action in a given scenario for a given user.
Accordingly, as described in the summary, three important aspects form the foundation of responsive supply chains. 1. Capture the context 2. Apply the context. 3. Learn from and enrich the context, in such a way that (all) the information needed for responsive decisions and actions, when the time of taking the decision and executing the action comes (as opposed to the time of planning the same), is captured upfront, and kept ready with relevant, qualified facts or at least a framework for qualification.
Why is this important? Why is this the most important aspect to address? Read a brief here. or revisit the problem statement deep dive here.
1. Capture the Context:
Important distinction – the objective is not just to capture the context of a given supply chain and then freeze it but to build a framework to ‘respond to’ changing environment and capture the changes and complex relationships. Recall the example described here – 100s of parameters interacting dynamically for a simple dock-door scenario.
Hence, Dynamism is key. Ad-hoc is key. And representing the real business environment, not the sterile theoretical reductions to a few parameters, is key. Capturing the context, in an extendable, reusable manner is the key.
We have two options. Option 1: Take static approach – integrations, with rigid data structures, requiring SI /EAI projects for every new data sources. Option 2: Dynamic, systemic way – extensible, changeable, responsive. Option 2 is possible with existing, proven technologies. This addresses the solution requirements presented in brief below, introduced here in the solution approach summary.
- A system to capture data, and changes to data.
- A system to capture relationships and changes to relationships.
- A system to control, limit, manage the created context.
Capturing data and relationships means this: capturing the specifics of supply chain, relevant to an industry, organization, customer, users, particular SKU etc., spread across internal and external sources. Not ALL but relevant and important aspects:
- Organizational context (e.g., cost to serve, margins, quality of revenue),
- Customer context (e.g., contractual outcomes, KPIs, margin sensitivity),
- Customer service context (e.g., agreed service level, cost tolerance, life-time-value potential)
- Employee context (e.g., current task, skills, safety, work-life balance),
- Environment (e.g., emissions, circularity), equipment (e.g., utilization, efficiency, distribution)
- Operational (e.g., processes, knowledge of expert operations users like store manager, product / category manager, warehouse operators, drivers, industry analyst, senior employees with extensive knowledge locked in their heads).
- Regulatory context (e.g., industry specific regulatory requirements, collaborative infrastructure)
- External sources (e.g., inputs from industry experts, operating environment, demand driving factors, volatility drivers specific to an industry established in practice or research).
- Along with the ability to enrich and evolve the context continuously – e.g. accommodating inputs from expert users, or machine observed patterns.
The point is, if we agree that supply chains are impacted by all of the above context and more, and if there is a system that can capture all of this readily, then why settle with systems which cannot even capture a fraction of this rich context?
Also keep in mind that any resilient system must have this context handy to be effective – supply chains do not work in the isolated world of IT systems.
Importantly, the solution approach allows for flexible extensions to the above context to capture the dynamism of real-life changes with time, not limited by functionally unrelated constraints (e.g. foreign key constraints in a database).
This flexible, evolving approach to establishing contextual relationships contrasts with the conventional approach of fixed, rigid integrations which cannot be changed once implemented.
This forms the foundation for modelling the rapidly changing industry context – e.g., IoT streaming data with real-life external events, supply chain or manufacturing events with continuous context capture from varied data sources including humans (experts).
To capture this complexity and dynamism of data sources and their relationships, we need to fall back on Maths based approach, superior to existing data technologies.
- A brief Mathematical pull-aside: Deeper pull here. Skip this if you are already convinced 😊.Why Category Theoretical approach to context capture?(if the question is what’s the need to capture (so much of) relationship dynamism, go here. For why can’t we use existing systems, go here.The dynamism, at the scale required, with complexity of 1000s of parameters changing frequently, with assurance on data quality and origin, cannot be handled by existing systems.Category Theory, a branch of Mathematics is developed for dynamic capture of context that can span types of data, types of data models and even types of data sources (e.g. IoT devices data with specific data structure, even unstructured data).Category Theoretical approach to data modelling and data mapping benefits not just context capture but also guarantees structure preservation, transformation and (data) model abstraction with mathematical guarantee to data quality, lineage, constraint compliance and constraint integrity, while enabling ad-hoc data modelling and composability, reusability, extensibility. The recommended approach will deliver advantages like creating accurate, mathematically guaranteed 100% constraint enforcement at rest, ingress / egress, normalization / de-normalization across millions of data-sets ; creating data-frames, discovering hidden relationships etc. besides giving an independent existence to data models which can be infinitely extended without logging into databases, and other magical advantages.Technically, the proposed approach allows data models to be extended flexibly by appending additional data models (relational, graph – homogenous or heterogenous) and incrementally as and when required, at the Abstract Category Theoretical Data Model level (details here), without touching the underlying native data models. Relationships can exist between relational and non-relational data sources. Relationships can also be established ad hoc, dynamically – eg., attaching data from IoT sensor data / Computer Vision inference models to a relational/any data model instantly.
A system to create and hold the context, based on the Categorical Data Model principles, will address the requirements we started off with – capture data, relationships and their dynamism, creating a web of contextual relationships representing reality on top of existing systems irrespective of underlying data model constraints. In addition, this approach bestows several Mathematical superpowers not possible with prevalent data management technologies – data lineage, sanctity not just at schema level but data (cell) level etc. – refer to attached pdf for details).
In addition, we need a system to control, limit, manage the created Context.
The end result of this step, Creating the Context, is a potential solution space – a space in terms of relevant data, the context, with the ability to rapidly merge and relate 1000s of data sources, including the affecting and affected business parameters and the ability to allow this structure to be changed frequently, rapidly in line with physical reality changes. Contrast this with how the context is captured today – simple metrics, simple business process definitions that cannot be changed once defined without a massive System Integration project, etc. Let’s call this Context Fabric.
2. Apply the Context
This is a system to manage decisions and actions by applying the context for specific scenarios and specific users, using a decision arbitration mechanism to optimize for the chosen optimization goals – e.g. efficiencies, service levels, emissions, work-life balance, with the knowledge of the cost of decision alternatives.
As a reminder, this complements existing systems – data sources, ETL mechanisms, data lakes, lake houses, warehouses and ML models. This improves the speed and accuracy of preparing relevant data, for the context of specific use case and end user persona, while training and running the deployed models, thanks to the ready context in the Context Fabric. Context Fabric forms the substrate for developing, training, and deploying Machine Learning models specific to scenarios and for specific operations use cases (time sensitive, field operations – drivers, pickers etc).
The data integrity, lineage and provability required for driving supply chain decisions and actions with confidence, is a natural outcome of using Category Theoretical approach. Rapidly creating this contextual data at the time of execution is not easy without context models. The qualified context models described above stitch all relevant facts together, create the context with real-time or current transactional data. This would not be possible to do in time for practical use without the self-learning, pre-qualified context models.
This approach (capture, learn and apply the context) provides the necessary framework for responsiveness in supply chains while optimizing for the specifics.
The solution approach is balancing two extremes simultaneously – the need for optimizing for specifics by capturing detailed context left out traditionally, and the need for responsiveness by being non-specific (open-ended, broad boundaries but with intelligence to qualify actions / decisions when required). This inter-play at every stage of the supply chain is the key differentiator.
At the time of execution, the solution guides the user to optimal action/decision, by
- Applying the scenario-specific ML models (developed separately for different use cases),
- Feed these models relevant data, using rapidly created contextual information.
ML models that leverage such contextual information will be more effective. But the time and costs required to create such deep context, while possible manually or with laborious integration / data engineering pipelines which will break at the sight of a new data source are not justifiable. Context Fabric approach makes this deep context possible and scalable for everyday use.
3. Learn from and enrich the Context
This system provides a feedback mechanism on top of the above context, to bridge planning and execution gaps by continuously sensing execution deviations from planned conditions and course-correcting in response, within the limits of the context-aware scenarios and with inbuilt feedback to channel the learnings from the context – patterns, situational sensitivities etc.
The solution approach creates reusable models of the context enrichment, for specific scenarios (use cases) and user profiles, unique to a given industry / organization / unit. The solution:
- Correlates and establishes various known relationships across data sources,
- Qualifies expert knowledge inputs and converts into reusable, weighted models,
- Discovers patterns, causal factors (e.g. demand drivers), situational sensitivity and awareness (e.g. vehicle lead time) for policy recommendations and updates the context models,
- Profiles users, customers (commercial, service level, contractual intelligence), transactional intelligence (opportunities) etc.
- Using these models, the context is learnt and updated continuously, progressively.
The result is a gradually strengthened, open-ended yet correlated definition of specific factors that influence supply chain volatility, the degree of freedom for decisions and actions, the levers to move in a situation-aware framework, finetuned for the use cases and users.
Here again, the Category Theoretical Data Modelling comes handy, enabling continuous, adhoc, almost infinite extensions and composing possibilities, so that the learnings can be applied back to enrich the context and also the feedback mechanism to control and course-correction to minimize deviations.
This concludes the 3 building blocks required to create first-principles supply chain solution that has the potential to be responsive, because it is designed to be responsive.
Enough for now. More details in a technical /architectural view of the solution in the next article.
Note: This builds on my earlier invention on applying Business Context on to IoT/RFID data, US Patent (US 7,394,379).